H T M L - Hyper Text Markup Language
2. HTML-seite
2.5 zeichensätze
Es ist zweckmäßig, im header jeder seite einen zeichensatz zu vereinbaren (vgl. 2.2.1), weil oft nicht klar ist, welchen zeichensatz der browser ohne diese vereinbarung verwendet. Der browser erwartet, dass die seite und ggf. eingabe-dateien in dem vereinbarten zeichensatz codiert sind. Der vereibarte zeichensatz wird auch verwendet, um dateiausgaben zu codieren. Wie die daten bei formulareingaben weitergegeben werden, ist einigermaßen unklar (siehe 9.1). Besondere bedeutung haben folgende zeichensätze:
Ansicode - ISO-8851-1
Alle zeichen werden mit einem byte codiert, dadurch ist der zeichensatz
auf 256 zeichen beschränkt. In der praxis sind es aber weniger, weil die
codierungen 0 – 31 für steuerzeichen reserviert sind, der code umfaßt aber
alle mit einer üblichen "deutschen" tastatur eingebbaren zeichen.
Unicode - UTF-8
Die zeichen werden mit einem oder zwei bytes codiert, dadurch ist der
verfügbare zeichenvorrat erheblich größer. Unicode gilt zu recht als
moderner und sollte bevorzugt verwendet werden.
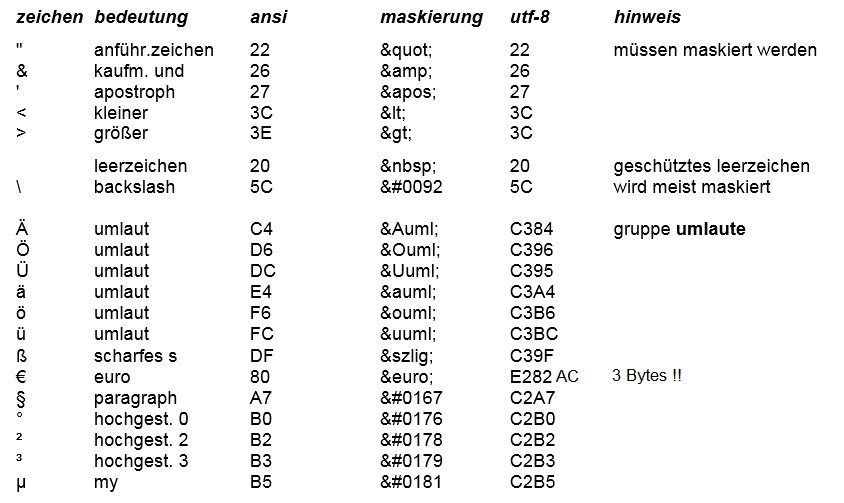
2.5.1 gruppe umlaute
Bezüglich der codierung des alphabets und der gängigen sonderzeichen
gleichen sich die zeichensätze Ansicode und Unicode bis auf
eine gravierende ausnahme: die hier als gruppe umlaute bezeichneten
zeichen (geschlossenen umlaute und die sonderzeichen ß, €, ³, °, ², ³ µ)
werden im Unicode mit zwei bytes codiert. Das führt zu problemen,
wenn der zeichensatz, mit dem die HTML-datei erstellt wurde nicht mit dem
zeichensatz übereinstimmt, der im header der seite mit charset
vereinbart ist. Einige besonderheiten bei der verarbeitung von
formularen werden unter ziffer 9.9 behandelt, probleme bei der verarbeitung
von dateien werden in der PHP-beschreibung behandelt und in der
MySQL-beschreibung finden sich hinweise zu den dort auftretenden
schwierigkeiten.
2.5.2 zeichen maskieren
Probleme gibt es auch mit den sog. kritischen zeichen, das sind zeichen,
die im HTML-code eine besondere bedeutung haben (", ', &, <, >). Diese
zeichen müssen maskiert werden (siehe 2.5.3). Auch das leerzeichen wird oft
maskiert, weil mehrere aufeinanderfolgende leerzeichen unbarmherzig auf
eines gekürzt werden (das ist eine der gemeinheiten von HTML). Maskiert
bleiben aber alle leerzeichen erhalten, man bezeichnet sie daher als
geschützte leerzeichen.
2.5.3 Codes, Maskierung
Nach dem muster &#nnnn kann man jedes zeichen mit seiner positionsnummer aus der code-tabelle des ASCII-codes maskieren.
hinweis
Bei der neuerstellung einer anwendung oder homepage sollte
man sich für einen zeichensatz entscheiden, alle seiten mit diesem
zeichensatz erstellen und diesen für den browser vereinbaren und dann dabei
bleiben. Ein späterer wechsel des zeichensatzes kann sehr aufwendig werden.
2.5.4 beispiele
Es sind inhaltlich völlig gleichartige seiten definiert,
die drei drei zeilen ausgeben:
- eine zeile mit den geschlossenen umlauten und dem zeichen ß
- eine zeile mit den gleichen zeichen, aber maskiert
- eine zeile mit den maskierten kritischen zeichen " € § & ' < >
| test1 | Die seite ist mit dem zeichensatz Ansicode erstellt und mit charset ist dieser zeichensatz vereinbart. |
| test2 | Die seite ist mit dem zeichensatz Unicode erstellt mit charset ist dieser zeichensatz vereinbart |
| Bei test1 und test2 gibt es keine probleme, das ergebnis ist in beiden fällen identisch | |
| test3 | Die seite ist mit dem zeichensatz Ansicode erstellt, mit charset ist aber Unicode vereinbart und es gibt probleme bei der darsellung der zeichen. |
| test4 | Die seite ist mit dem zeichensatz Unicode erstellt, mit charset ist aber Ansicode vereinbart. Erstaunlicherweise gibt es keine probleme bei der darstellung der zeichen, das ergebnis gleicht dem von test1 und test2. |
Fazit
Erstens man darf nicht unterschiedliche zeichensätze verwenden und zweitens
mit maskierten zeichen hat man keine probleme, allerding ist das
umständlich.